What is Retrieval Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
RAG is a software architecture that combines Large Language Models (LLMs) with business-specific information sources like documents and databases. This approach enhances the accuracy and relevance of the LLM’s responses, making them more precise and useful. Using vector database technology, RAG stores up-to-date information retrieved via semantic searches and adds it to the prompt’s context. This enables the LLM to formulate the best possible, current response with all relevant information considered. This architecture is famous for offering detailed, relevant answers by integrating LLMs’ knowledge with proprietary business data.
What are the advantages of Retrieval-Augmented Generation?
- Efficient Implementation: Chatbot development typically starts with a basic model. Foundation Models (FMs) are large accessible language models trained on a wide range of generic, unlabeled data. The computational and financial costs of retraining FMs with organization-specific or domain-related information are high. RAG provides a more convenient approach for introducing new data into LLMs, thereby increasing the accessibility and usability of generative AI technology.
- Current Information: Even if the original training sources for an LLM suit your needs, keeping the information relevant is challenging. RAG lets developers supply the latest research, statistics, or news to generative models. They can utilize RAG to link the LLM directly to frequently updated social media feeds, news sites, or other information sources. Consequently, the LLM can offer users the most recent information available.
- User Trust: RAG enables LLMs to present accurate information with source attribution. Output can include citations or references to sources. Users can even search for the original documents if further clarification or details are required. This increases trust and confidence in your generative AI solution.
- Developer Control: With RAG, developers can efficiently test and improve chat applications by managing and modifying the LLM’s information sources to meet changing requirements. They can restrict sensitive information retrieval based on authorization levels, ensuring appropriate responses. Additionally, they can correct the LLM if it references incorrect information sources. This increased control allows organizations to deploy generative AI technology more securely across various applications.
The combination of retrieval and generative processes offers several benefits:
- Accuracy: Responses are grounded in retrieved information, resulting in higher relevance and precision.
- Continuous Learning: RAG continually updates its knowledge base, enhancing its accuracy and relevance over time.
- Flexibility: RAG is capable of handling complex queries and is adaptable to a wide range of applications and industries.
How does RAG work?
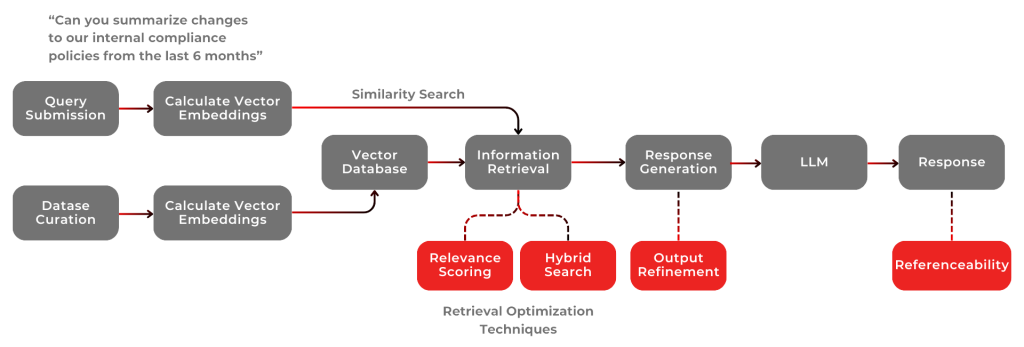
- Query Input: The process starts with the user entering a query or question that the RAG system needs to address.
- Retrieval Phase: In this phase, the system searches a large dataset or database to find information relevant to the input query. Algorithms that understand the query’s context are used to match it with appropriate data, quickly sifting through vast amounts of information to find the most pertinent data.
- Data Filtering and Ranking: After retrieving potentially relevant information, the system filters and ranks it based on relevance to the query. This step ensures that the most useful and accurate information is selected for the next phase. Ranking is based on factors like data recency, source credibility, and contextual match with the query.
- Generative Phase: With the relevant information retrieved and prioritized, the RAG system enters the generative phase. Here, a generative AI model uses the retrieved information to create a response that addresses the user’s query. This model produces new content that is contextually relevant and informed by the data from the previous phase.
- Response Output: The final output is a coherent and contextually relevant response generated by the AI model, tailored to effectively answer the user’s initial query.
- Feedback Loop (Optional): In some implementations, a feedback loop is included where the system learns from interactions. User feedback on the response’s accuracy and relevance can fine-tune the retrieval and generation processes for future queries.
RAG versus Traditional Decision-Making Tools
RAG employs a dynamic approach, in contrast to traditional decision-making tools that often rely on static datasets. By continuously integrating new data, RAG provides more pertinent and up-to-date responses. This adaptability is crucial in scenarios requiring rapid analysis and decision-making, distinguishing RAG from many conventional methods.
Retrieval Augmented Generation (RAG) limitations
By leveraging external data sources, RAG systems have the potential to enhance search quality, include proprietary data, and provide more accurate and contextually relevant results. However, despite their promise, RAG systems are not without their challenges and limitations.
- Confusing different meanings: one of the primary challenges in the retrieval phase is dealing with words that have multiple meanings. For example, the word “apple” can refer to the fruit or the technology company. RAG systems might struggle to distinguish between these different meanings, leading to the retrieval of incorrect or irrelevant information.
- Matching based on wrong criteria: Another limitation in the retrieval phase is RAG systems matching queries based on broad similarities, not specific details. For instance, when searching for information on “Retrieval-Augmented Generation (RAG),” the system might retrieve documents mentioning RAG. However, it may fail to capture the specific context or nuances of the query accurately.
- Difficulty in finding close matches: In large datasets, RAG systems may struggle to distinguish closely related topics, resulting in less accurate matches. This limitation is problematic when dealing with niche or specialized domains, where differences between concepts are subtle.
- Inadequate augmentation: naive RAG systems may struggle to properly contextualize or synthesize the retrieved data, leading to augmentation that lacks depth or fails to accurately address the nuances of the query. This can result in generated responses that are superficial or fail to capture the full scope of the information.
Conclusion
In conclusion, the use of Retrieval-Augmented Generation (RAG) in AInexxo‘s AI solutions highlights a significant advancement in information processing and accuracy.
AInexxo leverages the latest data structuring methodologies and cutting-edge research techniques to enhance the performance and reliability of their AI systems. This approach ensures that the information generated is not only accurate but also comprehensive, providing users with dependable and thoroughly vetted insights.