
The rapid evolution of Large Language Models (LLMs) showcases the swift advances in AI research and innovation. Beginning with basic language models, this progress has led to the creation of vast neural networks such as GPT-4, featuring billions of parameters.
Early Language Models:
(1960s) The 1960s introduced Eliza, the world’s inaugural chatbot, by Joseph Weizenbaum at MIT. Despite its rudimentary abilities, Eliza’s use of pattern recognition to simulate conversation laid foundational stones for Natural Language Processing (NLP) and the evolution of advanced language models.
(1970s) In the early 1970s, a significant advancement occurred in artificial intelligence with the introduction of the Hidden Markov Model (HMM), a breakthrough that dramatically expanded AI’s capabilities in analyzing data sequences. Subsequently, HMM’s expertise in forecasting sequence outcomes transformed fields such as computational linguistics, speech recognition, and bioinformatics. This evolution underscored its fundamental importance in enhancing the analytical capabilities of AI.
The advent of HMMs heralded a new era in the analytical capabilities of artificial intelligence systems. By leveraging the principles of probability, HMMs could model complex sequences, such as speech patterns, genetic sequences, and even financial transactions, with remarkable accuracy. This capability made them indispensable in fields ranging from computational linguistics and speech recognition to bioinformatics and financial modeling.
Progress in Neural Network Technologies
In the 1990s and early 2000s, N-gram models were key to statistical language modeling. Their simple yet effective approach, using word sequence probabilities, laid the groundwork for understanding language context. N-grams notably contributed to Google’s PageRank algorithm in 1996.
N-gram models emphasized context’s importance in language, paving the way for advanced methods to capture linguistic nuances.
Deep Learning Models
Furthermore, the 1990s saw the advent of Convolutional Neural Networks (CNNs), initially designed for image processing tasks. However, their utility extended to Natural Language Processing (NLP) applications, notably in text classification. These advancements in AI and neural network architectures, including the introduction of the Perceptron in 1960, along with RNN, LSTM, and CNN, have collectively transformed the field of natural language processing and deep learning. This evolution has paved the way for enhanced capabilities in understanding and processing human language, ushering in a new era of technological possibilities.
In 1986, the introduction of Recurrent Neural Networks (RNNs) marked a significant step forward in recognizing sequential patterns in language. However, RNNs encountered obstacles with long-range dependencies and issues related to vanishing gradients, highlighting the need for further innovation in the field.
In the early 1990s, Elman’s Recurrent Neural Network Language Model (RNNLM) made strides in language modeling by mapping short-term word sequences effectively. Yet, it faced challenges with long-range dependencies, prompting a quest for alternatives.
In 1997, Latent Semantic Analysis (LSA) by Landauer and Dumais emerged, leveraging high-dimensional spaces to reveal hidden textual relationships. Despite its limits in complex tasks, LSA offered crucial semantic insights, paving the way for further advances in language modeling.
The game changed with Long Short-Term Memory (LSTM) networks. LSTMs could retain information much longer, significantly boosting machine learning models’ ability to understand and generate nuanced text. This innovation greatly improved the generation of human-like text, marking a significant leap in language modeling.
The Age of Data Expansion
(2010s) The 2010s witnessed a revolution in Natural Language Processing (NLP) with the introduction of Word2Vec and GloVe. These techniques, leveraging the vast amounts of text data available on the internet, transformed NLP by embedding words into dense vector spaces. This innovation enabled machines to understand the intricate nuances and relationships between words, significantly enhancing their language processing capabilities.
The Transformers era
The language modeling space has experienced remarkable progress, notably since the publication of the Attention is All You Need paper by Google in 2017. This pivotal work introduced the concept of transformers, revolutionizing the natural language processing (NLP) world. Consequently, it has served as the foundation for nearly every advancement in NLP since then.
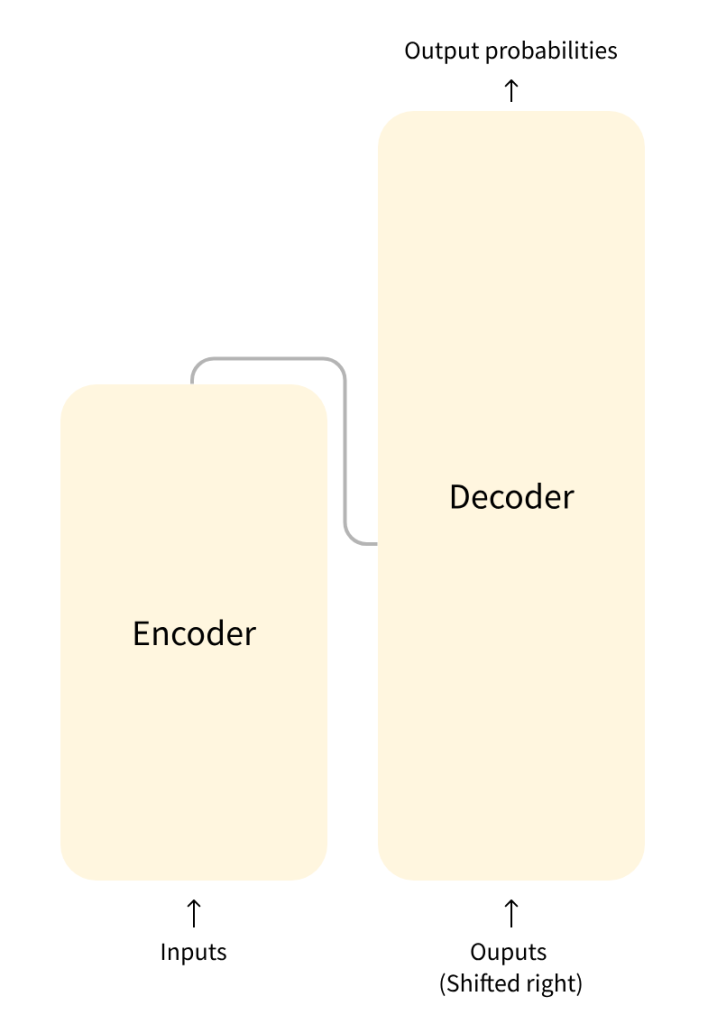
The model is primarily composed of two blocks:
- Encoder (left): The encoder receives an input and builds a representation of it (its features). This means that the model is optimized to acquire understanding from the input.
- Decoder (right): The decoder uses the encoder’s representation (features) along with other inputs to generate a target sequence. This means that the model is optimized for generating outputs.
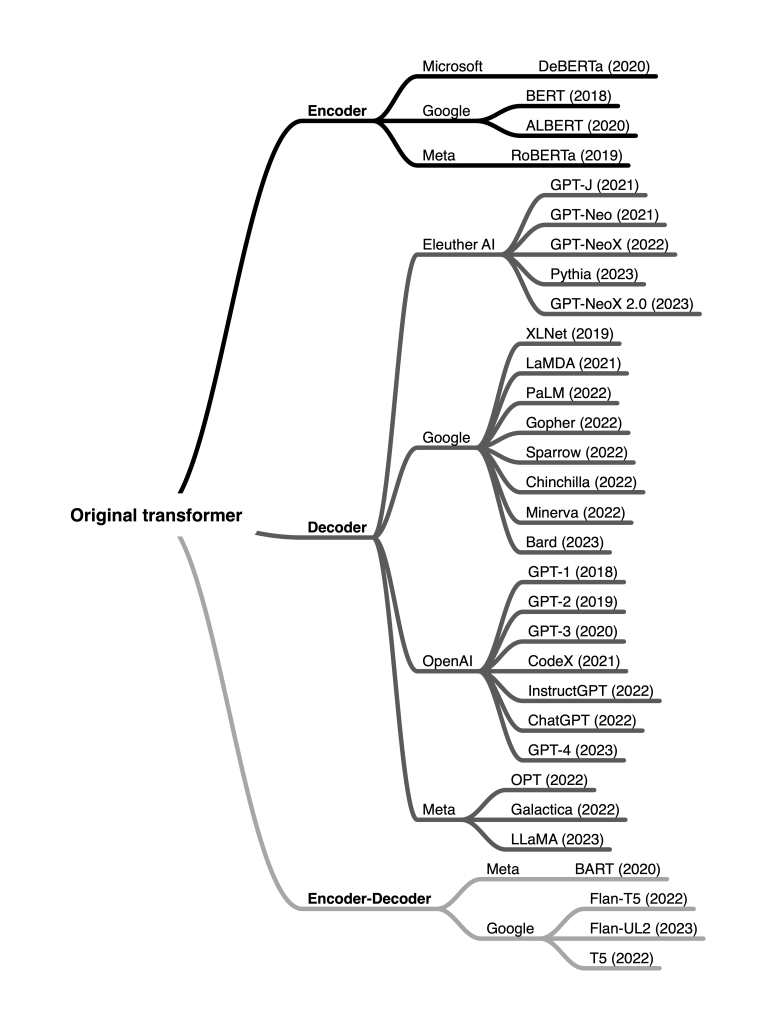
(2018) Google’s Launch of BERT marked a transformative moment in grasping the context of sentences. By employing bi-directional text analysis, BERT set new benchmarks in language comprehension, significantly outperforming previous models in question answering and language inference tasks. This breakthrough established a new benchmark for Large Language Models (LLMs), redefining expectations in the field.
The Current Landscape
In the present-day technological landscape, the advancement of Large Language Models like GPT-4 is reshaping the boundaries of artificial intelligence.
Among the top LLMs we find:
GPT-4 (OpenAI)
- Architecture: GPT-4 extends the transformer-based architecture, refining it for greater efficiency and scale. It pushes the envelope in terms of parameters and training dataset size, focusing on enhanced context understanding and generation capabilities.
- Innovations: Significant advancements in handling nuanced human-like text generation, improved context awareness, and a reduction in hallucinations and biases compared to its predecessors. It represents a leap in achieving closer-to-human performance in NLP tasks.
- Applications: Broad, ranging from content generation, complex language understanding, conversational AI, to domain-specific applications like programming assistance.
Mistral
Mistral AI, through its partnership with Microsoft Azure, has introduced Mistral Large, emphasizing the acceleration of AI innovation and the deployment of LLMs. This collaboration benefits from Azure’s AI supercomputing infrastructure, expanding Mistral AI’s reach in global markets and enhancing research collaborations
Mistral AI’s advancements and strategic partnerships represent a significant step forward in making AI technologies more open, efficient, and accessible, aligning with its commitment to innovation and the democratization of AI.
LLaMA-2 (Meta)
- Architecture: Building on Meta’s foray into efficient transformer models, LLaMA-2 would likely emphasize optimizations that reduce computational requirements without sacrificing performance. Meta has been focusing on creating models that can democratize access to cutting-edge AI by being more resource-efficient.
- Innovations: Expected to introduce enhancements in training methodologies, data utilization efficiency, and possibly novel approaches to mitigate common issues like bias and ethical considerations in model outputs.
- Applications: Aimed at a wide array of NLP applications, with a particular focus on making high-performance models more accessible and economical for a broader range of researchers and developers.
Falcon
Falcon LLM is a generative Large Language Model that helps advance applications and use cases to future-proof our world.
- Falcon 40B was the world’s top-ranked open-source AI model when launched. Falcon has 40 billion parameters and was trained on one trillion tokens. Falcon 40B is revolutionary and helps democratize AI and make it a more inclusive technology.
- Falcon 180B is a super-powerful language model with 180 billion parameters, trained on 3.5 trillion tokens. This model performs exceptionally well in various tasks like reasoning, coding, proficiency, and knowledge tests, even beating competitors like Meta’s LLaMA 2.
LLMs Comparative Analysis
- Architectural Principles: While GPT-4 and potentially LLaMA-2 build upon the transformer architecture, focusing on scale and data efficiency, it is the specifics of their implementations, including attention mechanisms, parameter tuning, and training regimes, that serve as crucial differentiators.
- Efficiency and Accessibility: Meta’s models, suggested by the LLaMA-2 reference, likely prioritize computational efficiency and broader access, addressing the high resource demands of training and deploying large-scale models.
- Innovations and Contributions: Each model contributes uniquely to the AI field, pushing boundaries in language understanding, generation capabilities, and application breadth.
LLMs vs and SLMs:
- Large Language Models (LLMs): LLMs, or Large Language Models, represent a sophisticated tier of AI designed to grasp, interpret, and produce human language. Initially, these models undergo extensive training on broad datasets and feature deep neural network architectures, with GPT-3 and BERT standing as prime examples. Consequently, LLMs excel at crafting coherent, contextually apt text, making them invaluable for applications that demand intricate language processing.
- Small Language Models (SLMs): SLMs, or Small Language Models, serve as more streamlined versions of their larger counterparts, specifically crafted for efficiency and agility. Initially, they undergo training on smaller datasets, and subsequently, they are fine-tuned for optimal performance in settings with constrained computational resources.
These models are transforming AI’s mimicry of human functions, including writing, conversation, summarization, translation, and creative content creation. Their sophisticated language processing and generation mirror human cognition, placing them at AI’s forefront.